Guardrails
This page serves as a catalog of guardrails. It explains the theory of operation and the specific configuration options for each type of guardrail. For in-depth usage instructions, see the Tutorials.
All guardrails operate on a common data model called the Entailment Frame. This is also documented here for each guardrail type.
Common Configuration
All guardrails share the same basic information fields.

- Guardrail ID: A generated UUID used to programmatically refer to the guardrail. This ID identifies to the Python client which guardrail to run.
- Application: The application container to which the guardrail belongs.
- Guardrail Name: A human-readable label for this guardrail. This is not used programmatically.
- Guardrail Type: The technique behind the guardrail; the rest of this page focuses on the different guardrail types.
Consensus
Theory of Operation
Consensus is an agentic guardrail that performs an LLM-as-a-Judge assessment of the query with several parallel LLM requests, consolidating their responses into a majority vote.
Entailment Frame
- Context: Optional background knowledge, e.g., RAG documents.
- Question: The question to be answered about the context (or from an LLM's parametric knowledge).
- Answer: An answer to the question to be verified.
- Eval: The overall assessment: Yes if the answer is deemed correct; No otherwise.
- Confidence: The percentage of judges in agreement.
- Proof: N/A
Configuration Options

- LLM: Which LLM to use for the judge. At this time, all judges use the same LLM.
- Iterations: The number of judges to use.
Consistency Checking
Theory of Operation
When an LLM "knows" something, it tends to provide a consistent response. However, when information is missing from its parametric memory (and from the context), it will still answer with its highest-probability guess. This is a common source of hallucination. The consistency checking guardrail will rephrase the context, question, and answer and ask the LLM to determine entailment: does the answer follow from the context and question? If it does, the LLM will consistently give the correct answer; widely different answers indicate uncertainty in the answer.
A semantic similarity score is used to weight the rephrasing results. This score is determined by taking the cosine distance in an embedding space between the original frame and the rephrased version.
Entailment Frame
- Context: Optional background knowledge e.g. RAG documents.
- Question: The question to be answered about the context (or from an LLM's parametric knowledge).
- Answer: An answer to the question to be verified.
- Eval: The overall assessment: Yes if the answer is entailed by the combination of context and question; No otherwise.
- Confidence: The degree of entailment.
- Proof: N/A
Configuration Options

- LLM: Which LLM to use for the primary assessment of entailment.
- Iterations: The number of rephrased samples to analyze.
- Utility LLM: Which LLM to use to perform the rephrases. Using a weaker LLM is often helpful to encourage variety.
- Embedding Model: Which embedding model to use for semantic similarity measurements between rephrasings.
Critique & Revise
Theory of Operation
Critique & Revise configures two adversarial agents that work together to verify the frame. The critique agent analyzes the context and question for entailment of the answer. Subsequently, the review agent will review the critique agent's assessment, and if it disagrees will provide feedback on why. This iterates until the two agents agree (or until a preset iteration limit has been reached). If this happens, the most recent critique result is returned as the final eval.
There is an additional counterfactual mode in which the critique agent attempts to generate counterfactuals that disprove entailment; it is more adversarial than the neutral critique agent in the default configuration.
Entailment Frame
- Context: Optional background knowledge e.g. RAG documents.
- Question: The question to be answered about the context (or from an LLM's parametric knowledge).
- Answer: An answer to the question to be verified.
- Eval: The overall assessment: Yes if the answer is entailed by the combination of context and question; No otherwise.
- Confidence: N/A
- Proof: N/A
Configuration Options

- LLM: Which LLM to use for the agents.
- Iterations: The number of iterations before ending the "debate".
- Counterfactuals: Check to enable counterfactual mode.
Entailment
Theory of Operation
Entailment is an agentic guardrail that uses a faithfulness metric to evaluate whether an answer is logically entailed by the provided context. This guardrail extracts individual factual claims from the answer and evaluates each claim against the context to determine if it can be inferred or supported by the given information.
The guardrail processes the answer by: 1. Breaking it down into individual claims based on configurable granularity 2. Evaluating each claim against the context using faithfulness scoring 3. Computing an overall entailment score as the average of individual claim scores 4. Providing detailed proof with per-claim analysis
Entailment Frame
- Context: Background knowledge and documents that should support the answer claims.
- Question: The question being answered (used for contextual evaluation).
- Answer: The answer to be verified for entailment against the context.
- Eval: The overall assessment: Yes if the answer claims are entailed by the context; No otherwise.
- Confidence: The average faithfulness score across all extracted claims (0.0-1.0).
- Proof: Detailed analysis including individual claim scores, support status, and reasoning for each claim.
Configuration Options
- LLM: Which LLM to use for claim extraction and evaluation.
- Evaluation Threshold: The confidence threshold (default 0.5) above which the entailment is considered positive.
- Claim Granularity: Controls how claims are extracted from the answer:
sentence- Extract each complete sentence as a separate claimclause- Extract each independent clause as a separate claimfine- Extract each atomic factual assertion as a separate claim
Human Review
Theory of Operation
Human Review is a manual review by human analysts, and uses no automation. The raw entailment frame is presented in the Human Review Dashboard as both input and output. Note: this is the same Dashboard that is optionally used for review of automation-produced assessments in some other guardrails.
Entailment Frame
- Context: Optional background knowledge e.g. RAG documents.
- Question: The question to be answered about the context.
- Answer: An answer to the question to be verified.
- Eval: The overall assessment: Yes if the answer is deemed correct; No otherwise.
- Confidence: N/A
- Proof: Open per organization's review guidelines.
Configuration Options
N/A
LLM-as-a-Judge
Theory of Operation
LLM-as-a-Judge uses an LLM agent to assess the accuracy and quality of an input frame. This relies on the ability of the configured LLM to reason over the frame internally.
Entailment Frame
- Context: Optional background knowledge e.g. RAG documents.
- Question: The question to be answered about the context (or from an LLM's parametric knowledge).
- Answer: An answer to the question to be verified.
- Eval: The overall assessment: Yes if the answer is deemed correct; No otherwise.
- Confidence: The percentage of judges in agreement.
- Proof: N/A
Configuration Options

- LLM: Which LLM to use for the judge.
Policy Rules
Theory of Operation
A common usage pattern for guardrails is to assess compliance of a chunk of input text against a written (natural language) policy.
When configuring a Policy Rules guardrail, we:
- Extract (from a complex policy document) a simplified list of (natural language) rules that demonstrate compliance.
- For each rule individually: formalize that rule into domain-specific language (DSL) code and generate natural language questions specific to that rule's variables. This rule-oriented approach keeps DSL and questions tightly scoped to each specific policy rule.
- The DSL code uses an SMT solver integrated with an LLM-powered system for verification, while questions are designed to be straightforward for LLM-powered data extraction or human-powered data review, avoiding complex reasoning when processing a chunk.
Rule Extraction Methods
The system supports two methods for extracting rules from policy documents:
-
Basic Method: Uses a simple LLM prompt to extract rules directly from the entire policy document.
-
RAG Method: Uses a sophisticated Retrieval-Augmented Generation (RAG) pipeline that:
- Chunks the policy document using semantic or size-based segmentation
- Extracts rules from each chunk in parallel
- Performs intelligent deduplication using semantic similarity
- Filters rules for topical relevance using advanced similarity algorithms
Filtering Strategies
When using the RAG method, you can choose between two filtering strategies to ensure extracted rules are relevant to your query theme:
-
Embedding Similarity: Uses cosine similarity between rule embeddings and query embeddings to filter rules. This approach is fast and works well for general topical filtering.
-
Provence Reranker: Uses a specialized neural reranker model (
naver/provence-reranker-debertav3-v1) that analyzes the semantic relationship between rules and the query. This approach provides more accurate filtering by understanding context and meaning at a deeper level, but requires additional computational resources for the first-time model download.
Both strategies use the same relevance threshold (0.0-1.0), where higher values result in more strict filtering and lower values are more permissive.
At inference time:
- The questions are asked (to an LLM) of the input chunk. Note that as not all parts of the policy may be addressed in a given chunk, not all questions need be answered.
- (Optional) LLM answers can be reviewed and corrected by a human analyst.
- The DSL is executed using these answers as inputs.
Entailment Frame
- Context: An input "chunk" to be analyzed for (non-)compliance with a configured policy.
- Question: An understood "Is this consistent with policy X?" (Practically speaking: continued context)
- Answer: N/A
- Eval: The overall assessment: Yes if the answer is deemed correct; No otherwise.
- Confidence: The percentage of rules (DSL assertions) that have been satisfied.
- Proof: A separate True/False (
1.0/0.0) result for each assertion, corresponding to each policy rule. This allows a detailed assessment of why an overall assessment is Yes/No.
Configuration Options

The following basic configuration items set up the Policy Rules configuration tool.
- LLM: Which LLM to use for answer extraction at inference time.
- Utility LLM: Which LLM to use for configuration-time rule extraction, code generation, and question generation.
- Embedding Model Which model to use for configuration-time rule extraction and relevance assessment.
- Human Review Enabled: Whether to pause inference and route extracted questions to the Human Review Dashboard for verification and correction.
- Completion Policy: Dropdown selection for how unknown/uncertain values are handled in assertions:
- Pessimistic (Recommended for compliance): Treats unknowns as failures - missing information causes checks to fail
- Neutral (Default): Reports unknowns explicitly without making assumptions
- Optimistic: Treats unknowns as passing - gives benefit of doubt when information is missing
The completion policy determines what policy annotation ([pessimistic], [neutral], or [optimistic]) is injected into generated DSAIL assertions. For regulatory compliance scenarios, always use Pessimistic to ensure that uncertain conditions fail rather than pass.
Rule-Oriented Configuration
Policy Rules guardrails use a rule-oriented configuration model where each extracted rule is independently configured:
- Per-Rule DSL Generation: Each rule can have its own DSL code generated independently. Click the "Generate DSL" button next to a specific rule to create/regenerate only that rule's code.
- Per-Rule Question Generation: Questions are generated for each rule based only on the variables declared in that rule's DSL code. Click "Generate Questions" next to a specific rule to create questions scoped to that rule.
- Rule Selection: Use the rule list on the left to navigate between rules. The currently selected rule's DSL and questions are shown in the editor and questions panel.
- Relevance Filtering: When using RAG extraction with a relevance threshold, the rule list dynamically filters to show only rules meeting the threshold. DSL and questions for filtered-out rules are preserved but hidden.
- Manual Editing: DSL code can be manually edited and will be automatically saved. Multiple assertions can be included in a single rule's DSL.
Playground Results Display
When testing Policy Rules guardrails in the playground, results are organized by rule:
- Rule-Based Grouping: Each rule appears as a separate collapsible card showing the original rule text, its DSL code, and relevant questions with answers.
- Combined Pass/Fail Logic: If a rule contains multiple DSL assertions, they are evaluated together: the rule shows ❌ (fail) if ANY assertion is unsatisfied, and ✓ (pass) only if ALL assertions are satisfied.
- Rule-Scoped Questions: Only questions whose variables are used in that specific rule's assertions are displayed, avoiding clutter from unrelated global questions.
Additionally, there are a number of fields pertaining to the analysis and configuration of the policy rules. These are described in the Policy Rules Tutorial.
Verification Guardrails for Policy Rules Questions
Policy Rules guardrails support an additional verification layer for enhanced answer reliability. When configuring questions in a Policy Rules guardrail, you can optionally assign a Verification Guardrail to each individual question.
Theory of Operation
When a verification guardrail is assigned to a question:
- The LLM first answers the question normally based on the input text
- The question, context, original text, and LLM's answer are submitted to the assigned verification guardrail
- If the verification guardrail returns a confidence score < 0.5, the answer is overridden to "UNKNOWN"
- All verification scores and override decisions are logged for audit purposes
Configuration
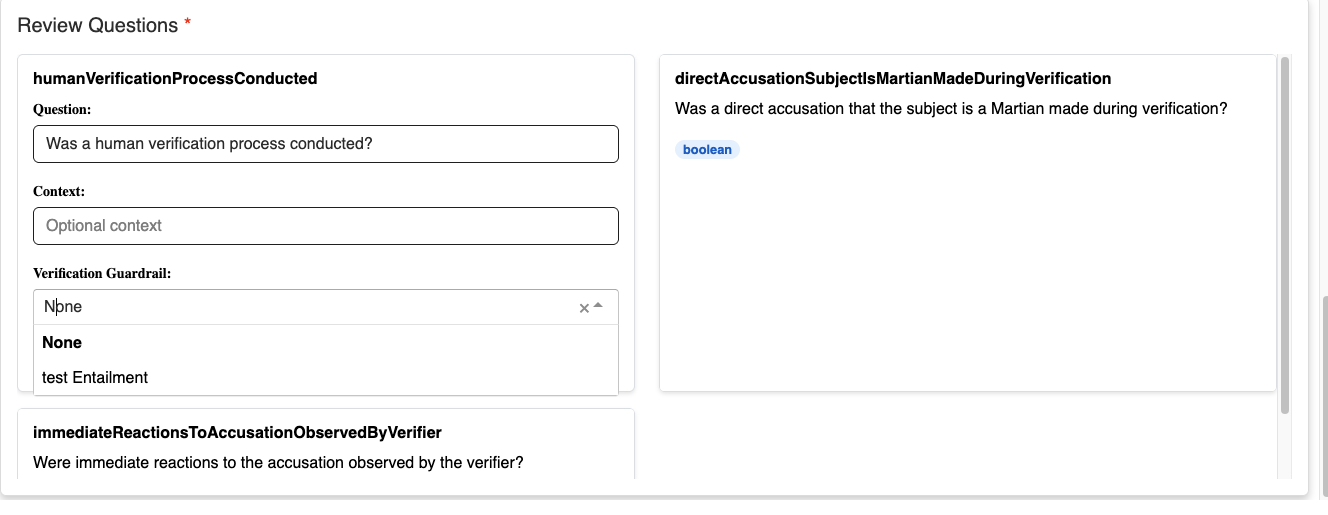
When editing questions in a Policy Rules guardrail:
- Verification Guardrail Dropdown: Select any guardrail within the same application (excluding other Policy Rules guardrails)
- Default: None (no verification performed)
Use Cases
Verification guardrails are particularly useful for:
- Critical Compliance Questions: Where incorrect answers have significant regulatory or business impact
- Ambiguous Text Scenarios: When the source text may be unclear or contradictory
- High-Stakes Decisions: Questions that drive important downstream processes
- Quality Assurance: Adding an extra validation layer for sensitive classifications
Consider, however, the extra compute cost for embedded verification guardrails, as full guardrails are run for each single question verified within the original policy rules guardrail.
Logging and Monitoring
All verification activities are logged with details including:
- Original LLM answer
- Verification score from the assigned guardrail
- Whether the answer was overridden to "UNKNOWN"
- Final answer used in the evaluation
This enables comprehensive audit trails and performance analysis of both the primary question-answering and the verification processes.
Complex Workflows
For advanced verification scenarios that require multiple guardrails working together, see the Applications documentation. Applications enable you to create DAG (Directed Acyclic Graph) workflows that orchestrate multiple guardrails with custom logic and dependencies.
Testing Guardrails
For interactive testing of individual guardrails and applications, see the Playground documentation. The Playground provides a user-friendly interface for testing verification scenarios without writing code.